
I Built a RAG Chatbot on My Own Newsletter. Here’s What I Learned
From vibe-coded prototype to boundary-defined system design

A few weeks ago, I built a chatbot trained entirely on my 200 content idea notes including my newsletter archive.
The idea was simple, to build a tool for my clients, friends, and honestly, the anxious part of me could message at 11:30pm when the spiral starts.
“Will I be replaced by AI?”
What I didn’t expect was this 👀:
Building it taught me why most vibe-coded AI apps feel impressive as prototypes but rarely survive as production systems.
Because the hardest part isn’t generating code.
It’s designing a system you can actually trust, measure, and improve.
First, What Is RAG?
RAG stands for Retrieval Augmented Generation.
Instead of relying purely on what an AI model already knows, you first retrieve relevant content from a knowledge base, then generate an answer grounded in that content.
Think of it like an open-book exam. The model doesn’t guess from memory, it looks things up first.
You see RAG in internal company knowledge bots, customer support chat, “Ask this document” features, and personal AI tools like what I built.
The goal is to reduce hallucination by anchoring responses in real data.
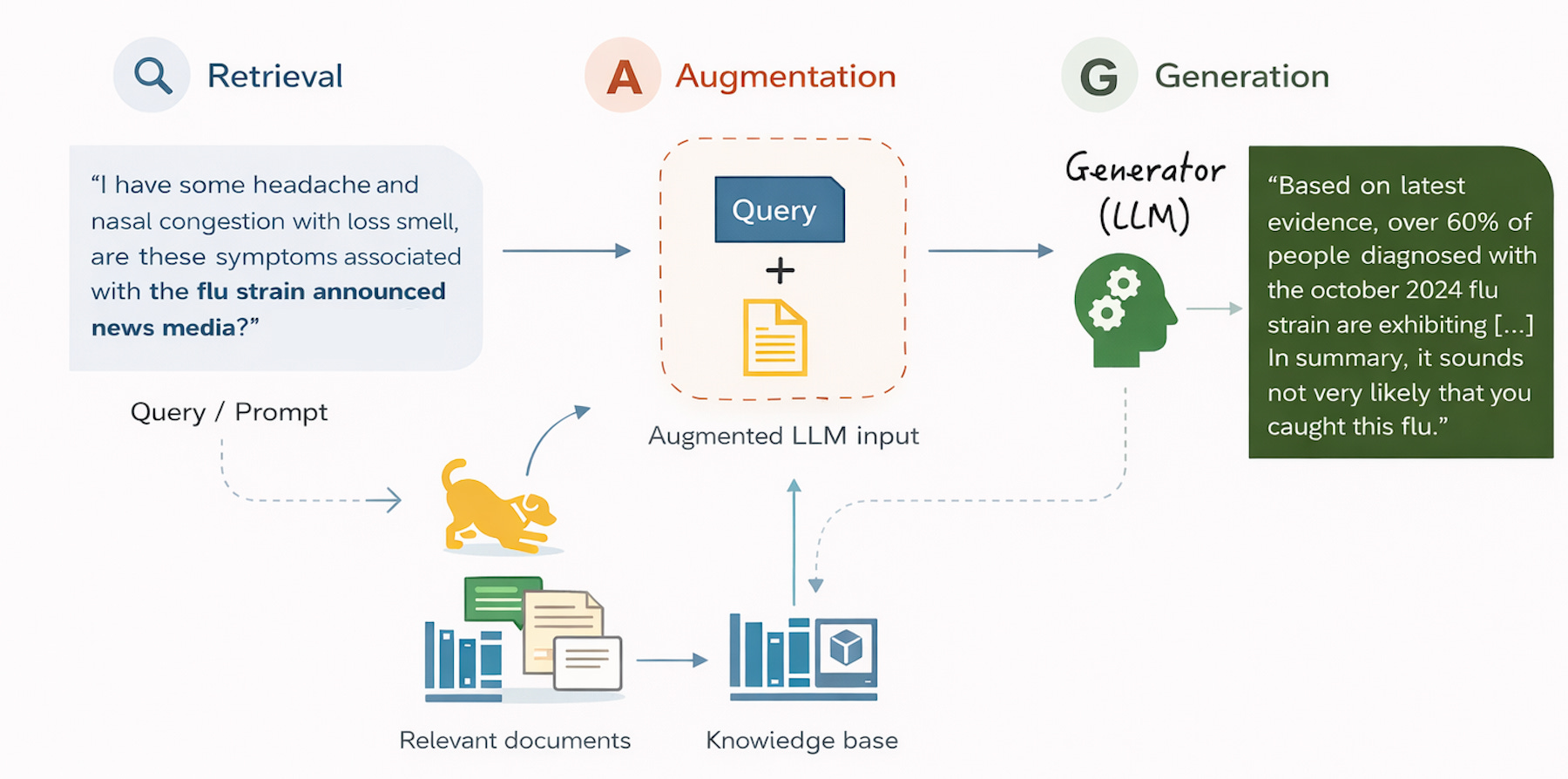
The workflow is pretty straightforward:
Chunk your documents into smaller pieces
Convert those chunks into vectors (embeddings)
Store them in a database
Retrieve relevant chunks when a question is asked
Feed those chunks to the LLM with the user query
Get accurate, grounded responses instead of hallucinations
Simple pipeline.
But design is where things get complicated.
The Two Ways to Build RAG
Classic RAG always retrieves before answering. Simple and predictable, but it pulls context even when it’s unnecessary, which adds irrelevant context, noise and latency.
Agentic RAG let the model decides whether retrieval is needed at all. More flexible, and potential better user experience, but it could introduce inconsistency, and is harder to evaluate.
I built the agentic version.
And that flexibility without clear boundaries became a design problem that I ran into.
When the System Behaves Inconsistently
I tested the RAG chatbot with: “How do I use AI to make money?”
It responded:
“While the context does not provide specific strategies for making money with AI…”, then it gave a loosely related answer anyway.
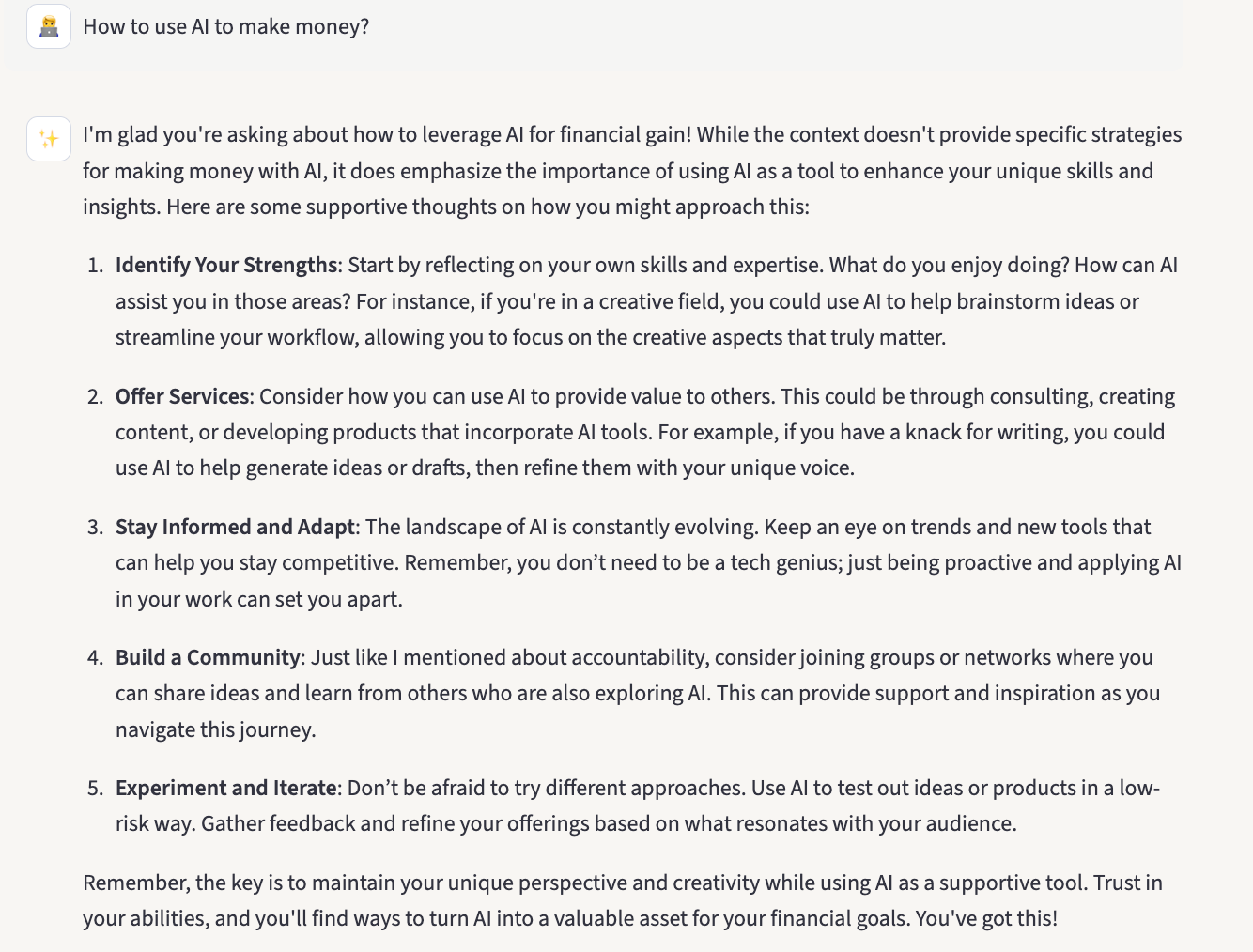
Technically, this was correct. But not helpful either.
Then I asked:
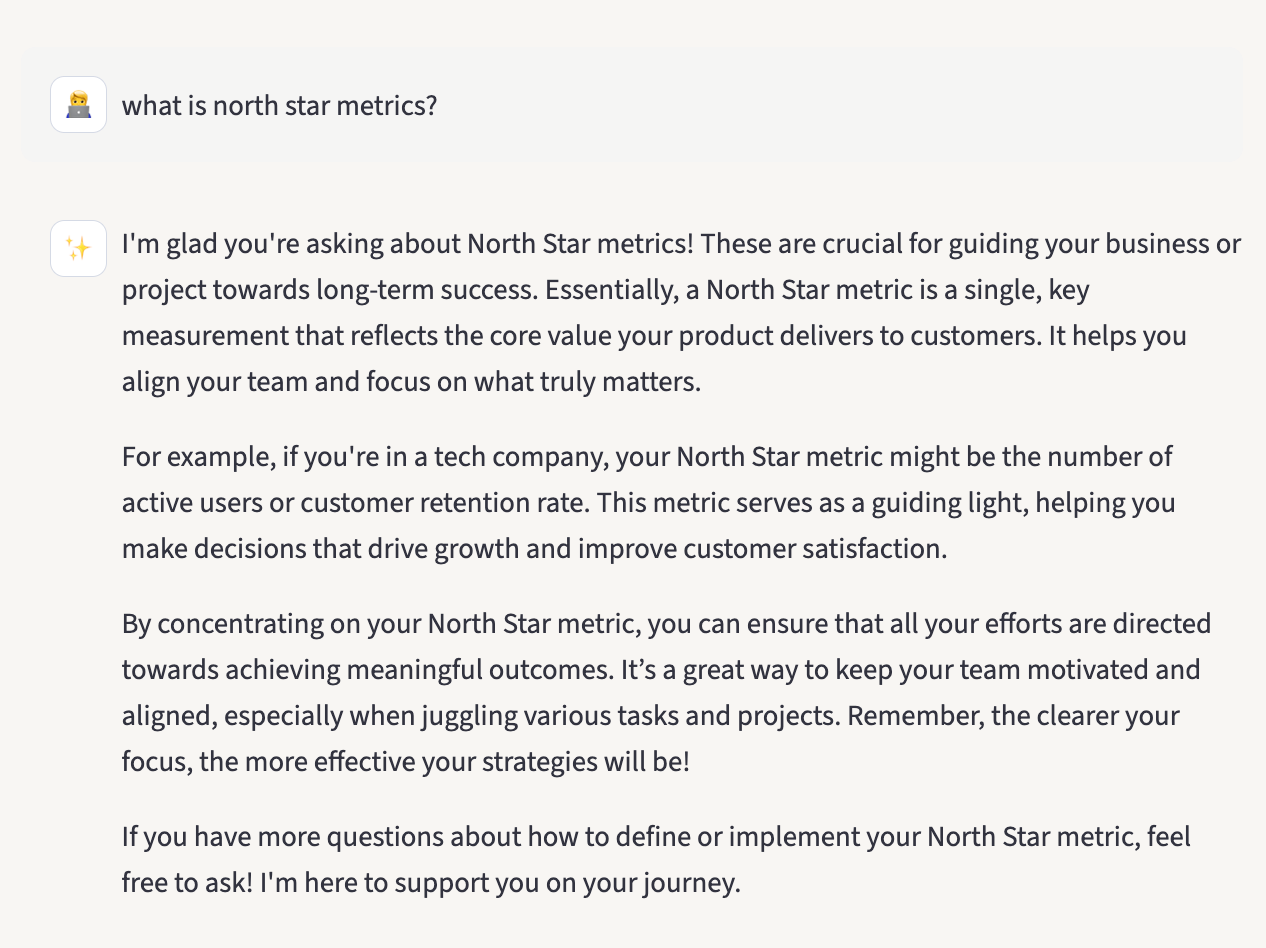
“What is north star metrics?”
It answered confidently, even though that phrase doesn’t appear anywhere in my documents.
But when I asked:
“Who is the president of the United States in 2026?”
It refused entirely.
Same system. Three questions. Three completely different behaviors. So what was actually going on?
The “make money” question had no good match in my knowledge base, but the system attempted an answer anyway rather than stopping.
The president question sat clearly outside my domain, so it declined.
“North star metrics,” on the other hand, overlaps with the business and growth language I write about, close enough that retrieval found something adjacent, and the model filled in the rest from general knowledge.
Each of these behaviors points to the same root cause:
I had built the pipeline, but I hadn’t defined the rules.
Here Is How I Improve It
Before touching chunk size or prompt tweaks, I had to define system boundaries.
Grounding policy
Should the system only answer if the exact information exists in the knowledge base?
Or can it answer anything thematically related?
Or should retrieval be optional context?Not choosing means the model defaults to something in between inconsistently.
Domain scope
What is explicitly in scope?
What should always trigger refusal?“North star metrics” slipped through because the model inferred my domain from semantic similarity rather than a clear definition.
If you don’t define this, the model approximations will go wrong and increase confusion.
Refusal rules and confidence thresholds
When retrieval finds something only loosely related, is that enough?
If you don’t set a threshold, the system will answer whenever it finds anything vaguely relevant.
Once these decisions are explicit, the system becomes predictable.
And predictability is what separates a vide-coded prototype from something you’d put in production.
To know whether the system is actually behaving according to those rules, you need metrics.
How to Actually Evaluate What You’ve Built
Once I saw the inconsistency, I know I need to improve it beyond intuition and started measuring.
RAG evaluation has two layers.
Retrieval evaluation
This checks whether the content is being pulled correctly before generating a single word. Three metrics matter here:Precision at k: of the top results retrieved, how many were actually relevant?
Recall at k: did the system retrieve the right content at all?
Mean reciprocal rank: how early did the correct content appear?
Think of it as grading the search engine, not the answer.End-to-end evaluation
This looks at the final response quality. In practice, this means manually reviewing a sample of outputs.It’s recommended to review at least 20 to 100 responses in production systems, and categorizing failures: retrieval failures, tone mismatches, generic answers, repetitive phrasing.
When I did this, I noticed many of my responses ended with “You’ve got this.”
Apparently I write that a lot lol.
The model learned it and repeated it everywhere which is something I want it to stop.
Once you categorize failures, we have a system for improvement and it becomes measurable iteration.
💭 Final Thoughts
Building the chatbot took a weekend.
Understanding how it should behave took much longer.
That gap is why most AI prototypes stay prototypes.
It’s easy to generate a demo, but without defined boundaries, metrics, and iteration, it is not ready for production. ⚙️
The AI skill that matters most isn’t just prompting a product.
It’s knowing why your system does what it does, catching it when it drifts, and being able to make it measurably better with intention.
Anyone can ship version one.
The practitioners who stand out are the ones who can prove why version five is better than version two.
Xoxo,